|
Zhecheng Yu 余喆诚 I'm a fourth-year undergraduate student supervised by Prof. Yan Lyu at Training Base for Top Students in Computer Science, Southeast University, Nanjing, China. I was a visiting scholar working with Prof. Brian Y. Lim at NUS Ubicomp Lab, National University of Singapore, Singapore. I'm currently an AI researcher (internship) working in the embodied perception group, Knowin AI, Shenzhen, China. I'm interested in human-centered designs. |

|
Researchhighlight denotes first-author works; purple denotes supervisors; * denotes equal contributions; † denotes corresponding authors. |
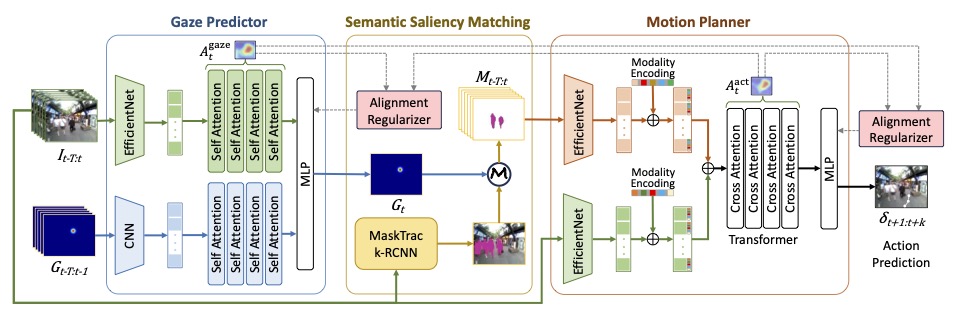

Learning from Human Gaze: Human-like Robot Social Navigation in Dense
Crowds
AAAI 2026
We introduce GazeNav, a real-world eye-tracking dataset in dense crowds, and
propose Gaze2Nav, a navigation framework that mimics human gaze to identify
socially salient pedestrians, achieving more human-like robot navigation.
|
ProjectsHere are my projects built based on my interests or engineering needs. |
|
Eye tracking and interaction in the virtual environment
2024
This project implements an egocentric virtual-world eye tracking system that supports real-time
visualization of gaze and hover (or select) behavior. Built on the Meta Quest Pro headset and
leveraging the Meta Movement SDK, it is developed in Unity and can also be integrated with XR,
enabling researchers and developers to analyze user attention and interaction patterns with
objects within immersive virtual environments.
👈 Click to play a video demo. |
Learning NotesHere are my learning notes compiled based on various open-source materials and my personal understanding. |
|
Introduction to Flow Matching and Diffusion Models
2025
Diffusion and flow-based models have become the state of the art for generative AI across a wide
range of data modalities, including images, videos, shapes, molecules, music, and more! This
course aims to build up the mathematical framework underlying these models from first
principles. At the end of the class, students will have built a toy image diffusion model from
scratch, and along the way, will have gained hands-on experience with the mathematical toolbox
of stochastic differential equations that is useful in many other fields. This course is ideal
for students who want to develop a principled understanding of the theory and practice of
generative AI.
Robot Foundation Models
2026
This note covers the latest advances in robot foundation models, including
Vision-Language-Action (VLA) architectures and World Action Models (WAMs). They cover how
large-scale pre-training on diverse data enables generalist robot policies and methods for
improving real-world manipulation and dexterity.
|

|
© Modify from Jon Barron. Do not scrape the HTML from this page itself, as it includes analytics tags that you do not want on your own website — use the github code instead. |